Biography
I am an ex-Neuroscientist now working on Artificial General Intelligence.
I’m working as a Staff Research Scientist at Google DeepMind, more precisely on Concepts understanding, structured representation learning and RL.
Basically worked a long while on unsupervised structure learning and generative models, leveraging them to make predictions and trying to make model-based Deep Reinforcement learning work like it should.
But like everybody, more recently I’m mostly working with assessing massive visual-language models for their common-sense abilities, like an ex-neuroscientist would 😃
- Machine Learning
- Unsupervised Structure Learning
- Deep Reinforcement Learning
- Computational Neuroscience
PhD in Computational Neuroscience and Machine Learning
UCL Gatsby Computational Neuroscience Unit
MSc in Computer Science / Biocomputing
Ecole Polytechnique Federale de Lausanne (EPFL)
Skills
Experience
Lead a variety of research efforts tackling several core AI problems.
Includes:
- Model-based RL leveraging structured generative models and Transformer-based world models.
- Episodic learning of object abstractions
- Video structured generative models and diffusion models
Responsibilities:
- Research & Tech lead and management (~10 Scientists/Engineers)
- Model building, training and optimization for large-scale distributed systems
- Analysis, presentation to core stakeholders.
- Integration, testing and debugging
Field defining research on object-based/structured generative models, and how to leverage them for learning better autonomous agents (e.g. graph neural networks).
- Research lead and core contributor (~3 Scientists/Engineers)
- Disentanglement research, environment development, benchmarks and advanced data collection.
- Deep Reinforcement Learning research (model-free, model-based, planning)
Core research on concepts and generative models, co-author on papers that started the disentanglement representation research sub-field.
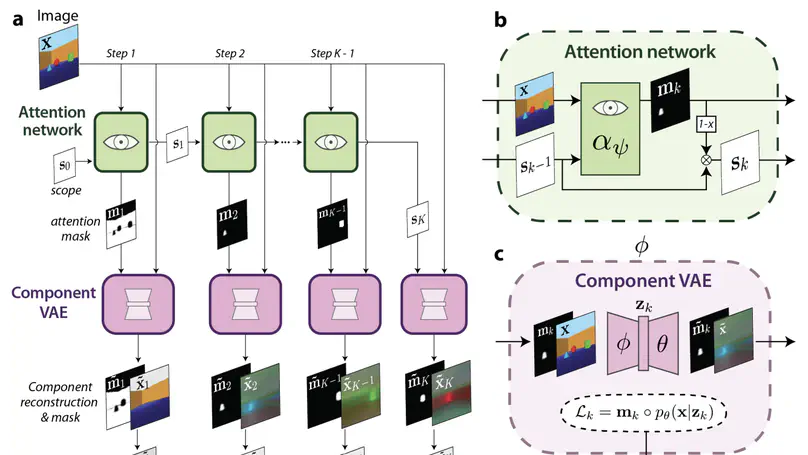
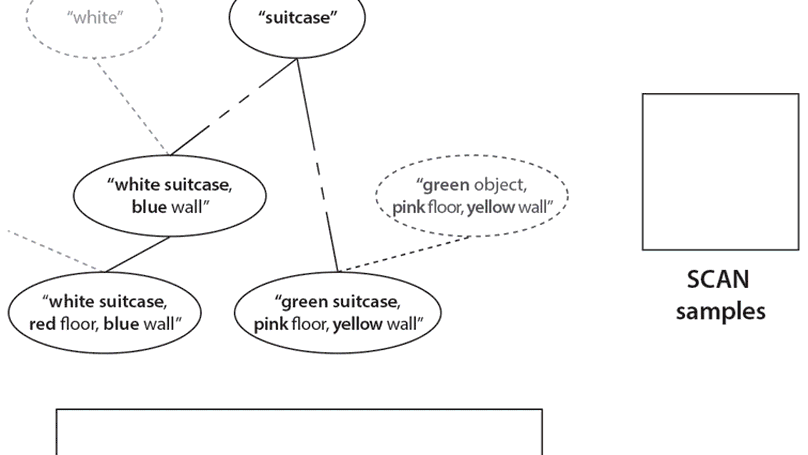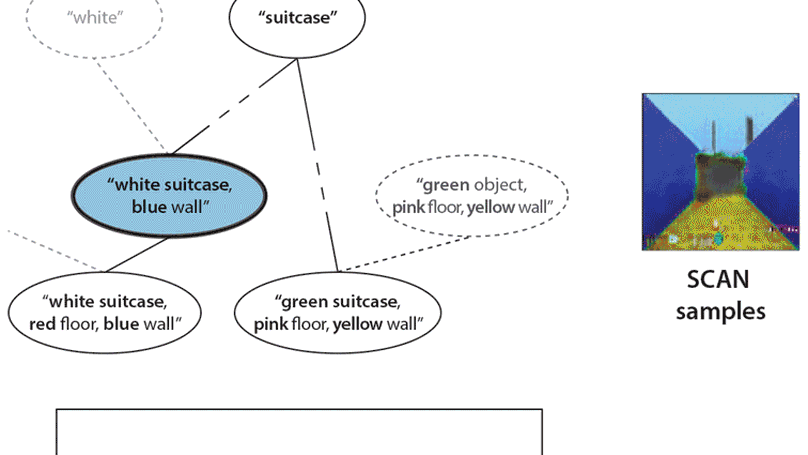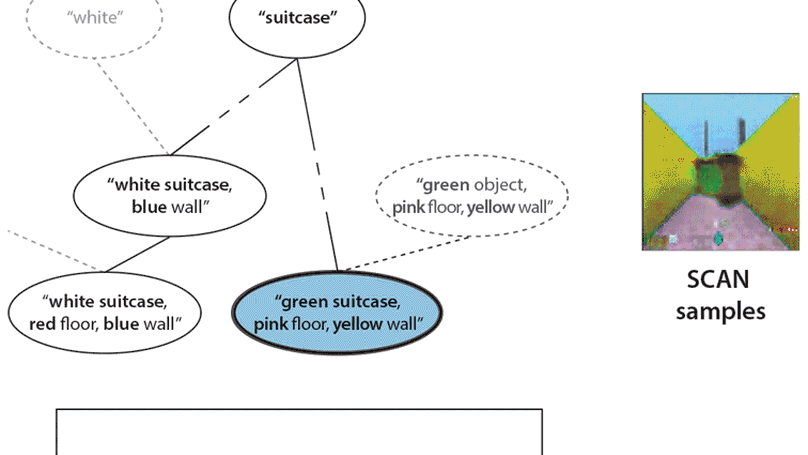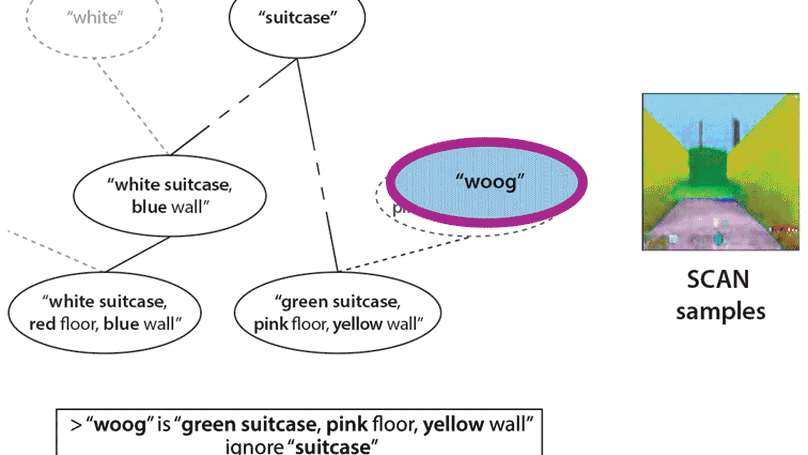
- Main co-author on β-VAE (4400 citations), Understanding Disentangling, SCAN, DARLA, MONet, IODINE, and many others.
- Designed and released the dSprites dataset, among other core datasets used by the community.
Featured Publications



Recent Publications

Contact
- loic@matthey.me
- London, UK
- Resume